moteur d’inférence#
Xinference prend en charge différents moteurs d’inférence pour différents modèles. Après avoir sélectionné un modèle, Xinference choisit automatiquement le moteur approprié.
llama.cpp#
Xinference supporte actuellement xllamacpp, développé par l’équipe Xinference, comme backend llama.cpp. llama.cpp est développé sur la base de la bibliothèque de tenseurs ggml, prenant en charge l’inférence des modèles de la série LLaMA et de leurs variantes.
Avertissement
Depuis Xinference v1.5.0, xllamacpp est devenu l’option par défaut pour llama.cpp, et llama-cpp-python a été déprécié ; à partir de Xinference v1.6.0, llama-cpp-python a été supprimé.
Veuillez vous référer à la définition de la structure common_params dans common.h de llama.cpp pour définir les paramètres.
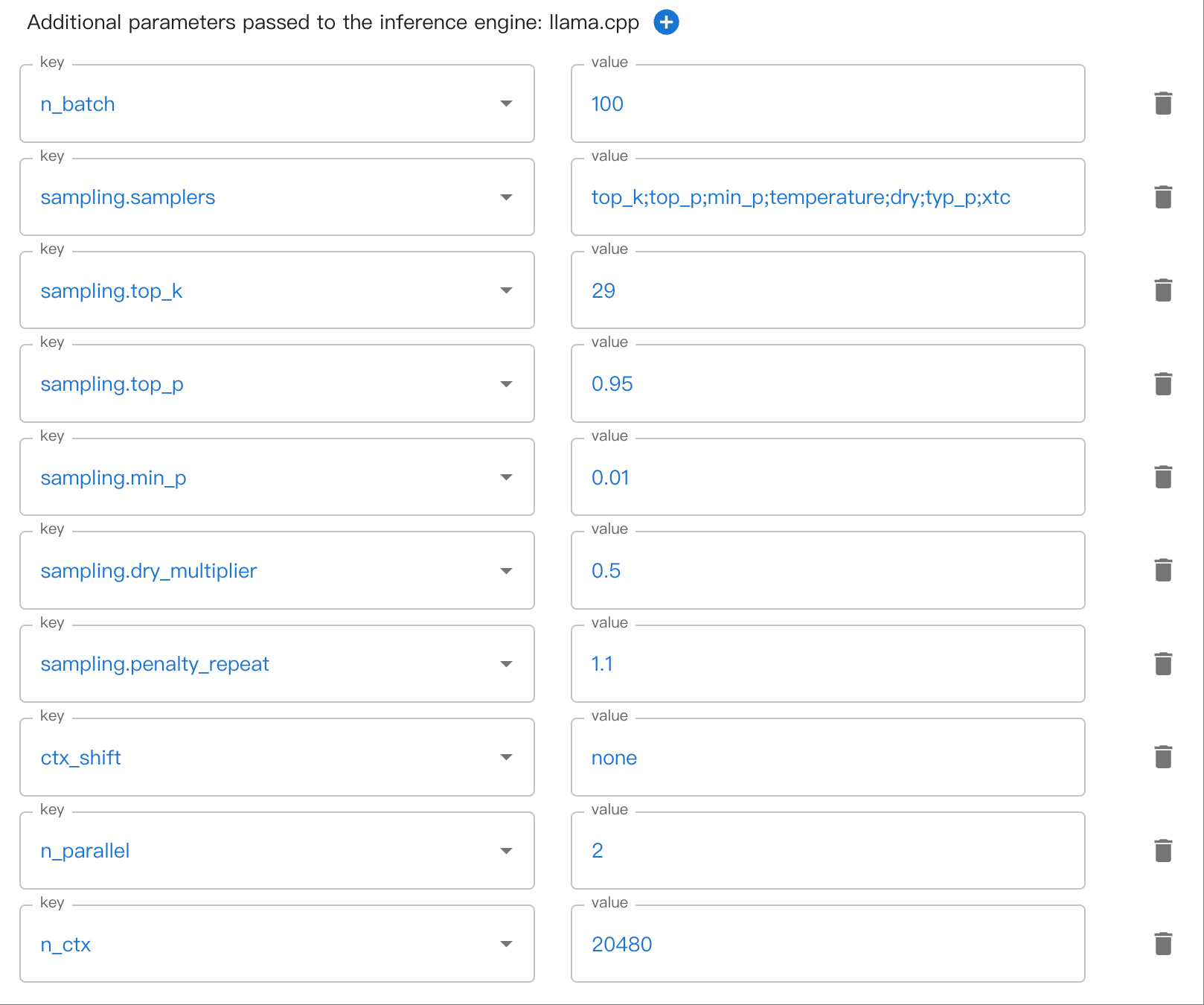
Il peut y avoir des paramètres imbriqués sur plusieurs niveaux. Par exemple, sampling.top_k. Veuillez utiliser . pour séparer les paramètres imbriqués.
Voici un exemple de configuration des paramètres d’échantillonnage imbriqué dans l’interface WebUI :
NGL automatique#
Ajouté dans la version v1.6.1: Depuis la v1.6.1, lorsque n-gpu-layers n’est pas spécifié (par défaut -1), l’estimation du nombre de couches GPU est automatiquement activée.
Cette fonctionnalité peut définir automatiquement le nombre de couches GPU (NGL) pour le backend llama.cpp. Veuillez noter qu’il ne s’agit pas d’un calcul précis, donc le résultat -ngl peut ne pas être optimal, et vous pourriez toujours rencontrer des erreurs de mémoire vidéo insuffisante.
Actuellement, NGL automatique n’a pas de support officiel. Veuillez vous référer au problème ci-dessous pour plus de détails :
Notre implémentation est basée sur le NGL automatique d’Ollama, mais avec quelques différences :
Nous utilisons les informations sur les périphériques fournies par xllamacpp.
Nous avons supprimé la prise en charge de certaines architectures peu courantes, qui utilisaient la logique de calcul par défaut.
Si le NGL automatique échoue, nous essayons de tout charger sur le GPU.
Nous ne supportons pas l’intégration de projecteurs multimodaux dans le modèle GGUF. Ce format de modèle est actuellement encore en phase expérimentale.
Foire aux questions#
Server error: {“code”: 500, “message”: “failed to process image”, “type”: “server_error”}
Journal du serveur :
encoding image or slice... slot update_slots: id 0 | task 0 | kv cache rm [10, end) srv process_chun: processing image... ggml_metal_graph_compute: command buffer 0 failed with status 5 error: Internal Error (0000000e:Internal Error) clip_image_batch_encode: ggml_backend_sched_graph_compute failed with error -1 failed to encode image srv process_chun: image processed in 2288 ms mtmd_helper_eval failed with status 1 slot update_slots: id 0 | task 0 | failed to process image, res = 1
Peut-être dû à un manque de mémoire. Vous pouvez essayer de réduire
n_ctxpour résoudre le problème.Server error: {“code”: 400, “message”: “the request exceeds the available context size. try increasing the context size or enable context shift”, “type”: “invalid_request_error”}
Si vous utilisez la fonctionnalité multimodale,
ctx_shiftest désactivé par défaut. Essayez d’augmentern_ctxou de réduiren_parallelpour augmenter la taille de contexte de chaque slot.Server error: {“code”: 500, “message”: “Input prompt is too big compared to KV size. Please try increasing KV size.”, “type”: “server_error”}
Journal du serveur :
ggml_metal_graph_compute: command buffer 1 failed with status 5 error: Insufficient Memory (00000008:kIOGPUCommandBufferCallbackErrorOutOfMemory) graph_compute: ggml_backend_sched_graph_compute_async failed with error -1 llama_decode: failed to decode, ret = -3 srv update_slots: failed to decode the batch: KV cache is full - try increasing it via the context size, i = 0, n_batch = 2048, ret = -3
Cela peut être dû à un échec de création du cache KV. Vous pouvez résoudre ce problème en réduisant
n_ctx, en augmentantn_parallel, ou en ajustant le paramètren_gpu_layerspour charger partiellement le modèle sur le GPU. Veuillez noter que si vous ne traitez que des requêtes d’inférence en série, l’augmentation den_paralleln’améliorera pas les performances.
transformers#
Transformers prend en charge la grande majorité des nouveaux modèles. C’est le moteur par défaut utilisé pour les modèles au format Pytorch.
vLLM#
vLLM est un moteur d’inférence de modèle de langage de grande taille très efficace et facile à utiliser.
vLLM présente les caractéristiques suivantes :
Débit de raisonnement de pointe
Utiliser PagedAttention pour gérer efficacement la mémoire des clés et des valeurs d’attention
Traitement par lots continu des requêtes entrantes
Noyau CUDA optimisé
Lorsque les conditions suivantes sont remplies, Xinference sélectionne automatiquement vLLM comme moteur d’inférence :
Le format du modèle est
pytorch,gptq,awq,fp4,fp8oubnb.Lorsque le format du modèle est
pytorch, l’option de quantification doit êtrenone.Lorsque le format du modèle est
awq, l’option de quantification doit êtreInt4.Lorsque le format du modèle est
gptq, les options de quantification doivent êtreInt3,Int4ouInt8.Le système d’exploitation est Linux et possède au moins un périphérique prenant en charge CUDA.
Les champs
model_familydes modèles personnalisés etmodel_namedes modèles intégrés se trouvent dans la liste de support de vLLM.
Actuellement, les modèles pris en charge incluent :
code-llama,code-llama-instruct,code-llama-python,deepseek,deepseek-chat,deepseek-coder,deepseek-coder-instruct,deepseek-r1-distill-llama,gorilla-openfunctions-v2,HuatuoGPT-o1-LLaMA-3.1,llama-2,llama-2-chat,llama-3,llama-3-instruct,llama-3.1,llama-3.1-instruct,llama-3.3-instruct,minicpm5-1b,tiny-llama,wizardcoder-python-v1.0,wizardmath-v1.0,Yi,Yi-1.5,Yi-1.5-chat,Yi-1.5-chat-16k,Yi-200k,Yi-chatcodestral-v0.1,mistral-instruct-v0.1,mistral-instruct-v0.2,mistral-instruct-v0.3,mistral-large-instruct,mistral-nemo-instruct,mistral-v0.1,openhermes-2.5,seallm_v2Baichuan-M2,codeqwen1.5,codeqwen1.5-chat,deepseek-r1-distill-qwen,DianJin-R1,fin-r1,HuatuoGPT-o1-Qwen2.5,KAT-V1,marco-o1,qwen1.5-chat,qwen2-instruct,qwen2.5,qwen2.5-coder,qwen2.5-coder-instruct,qwen2.5-instruct,qwen2.5-instruct-1m,qwenLong-l1,QwQ-32B,QwQ-32B-Preview,seallms-v3,skywork-or1,skywork-or1-preview,XiYanSQL-QwenCoder-2504llama-3.2-vision,llama-3.2-vision-instructbaichuan-2,baichuan-2-chatInternLM2ForCausalLMqwen-chatmixtral-8x22B-instruct-v0.1,mixtral-instruct-v0.1,mixtral-v0.1cogagentglm-edge-chat,glm4-chat,glm4-chat-1mcodegeex4,glm-4vseallm_v2.5orion-chatqwen1.5-moe-chat,qwen2-moe-instructCohereForCausalLMdeepseek-v2-chat,deepseek-v2-chat-0628,deepseek-v2.5,deepseek-vl2deepseek-prover-v2,deepseek-r1,deepseek-r1-0528,deepseek-v3,deepseek-v3-0324,Deepseek-V3.1,moonlight-16b-a3b-instructdeepseek-r1-0528-qwen3,qwen3minicpm3-4binternlm3-instructgemma-3-1b-itglm4-0414minicpm-2b-dpo-bf16,minicpm-2b-dpo-fp16,minicpm-2b-dpo-fp32,minicpm-2b-sft-bf16,minicpm-2b-sft-fp32,minicpm4Ernie4.5Qwen3-Coder,Qwen3-Instruct,Qwen3-Thinkingglm-4.5,GLM-4.6,GLM-4.7gpt-ossseed-ossQwen3-Next-Instruct,Qwen3-Next-ThinkingDeepSeek-V3.2,DeepSeek-V3.2-ExpMiniMax-M2,MiniMax-M2.5,MiniMax-M2.7GLM-4.7-Flashglm-5,glm-5.1DeepSeek-V4-Flash,DeepSeek-V4-Pro
SGLang#
SGLang dispose d’un runtime d’inférence haute performance basé sur RadixAttention. Il accélère considérablement l’exécution de programmes LLM complexes en réutilisant automatiquement le cache KV entre plusieurs appels. Il prend également en charge d’autres techniques d’inférence courantes, telles que le traitement par lots continu et le parallélisme tensoriel.
MLX#
MLX offre un moyen d’exécuter efficacement les LLM sur les puces Apple Silicon. Lorsque le modèle est au format MLX, il est recommandé aux utilisateurs de Mac équipés de puces Apple Silicon d’utiliser le moteur MLX.