Inférence distribuée#
Certains modèles linguistiques, y compris DeepSeek V3, DeepSeek R1, etc., sont trop volumineux pour être adaptés aux GPU d’une seule machine. Xinference prend en charge l’exécution de ces modèles sur plusieurs machines.
Ajouté dans la version v1.3.0.
Moteurs pris en charge#
Maintenant, Xinference prend en charge les moteurs suivants pour exécuter des modèles sur plusieurs workers.
SGLang (pris en charge dans la v1.3.0)
vLLM (pris en charge dans v1.4.1)
MLX (pris en charge depuis v1.7.1) ne supporte pas encore tous les modèles en mode distribué. Actuellement, les types de modèles suivants sont pris en charge. Si vous avez d’autres besoins, n’hésitez pas à soumettre une issue GitHub sur xorbitsai/inference#issues pour demander leur prise en charge.
DeepSeek v3 et R1
Qwen2.5-instruct et autres modèles ayant la même architecture de modèle.
Qwen3 et les autres modèles ayant la même architecture de modèle.
Qwen3-moe et d’autres modèles ayant la même architecture de modèle.
Utiliser#
Premièrement, vous avez besoin d’au moins 2 nœuds de travail pour prendre en charge l’inférence distribuée. Veuillez consulter Exécution de Xinference dans un cluster pour créer un cluster Xinference comprenant un nœud superviseur et des nœuds de travail.
Notes concernant vLLM (v0.11.0+) : À partir de la version vLLM v0.11.0, un déploiement distribué avec vLLM nécessite Xinference >= v1.17.1. En plus du paramètre existant --n-worker, il faut également définir tensor_parallel_size (en le réglant sur le nombre de GPU) et pipeline_parallel_size=1 lors du démarrage du modèle.
Ensuite, si vous utilisez l’interface Web, sélectionnez le nombre de machines souhaité comme worker count dans la configuration optionnelle ; si vous utilisez la ligne de commande, ajoutez --n-worker <nombre de machines> lors du démarrage du modèle. Le modèle sera alors lancé sur plusieurs nœuds de travail en conséquence.
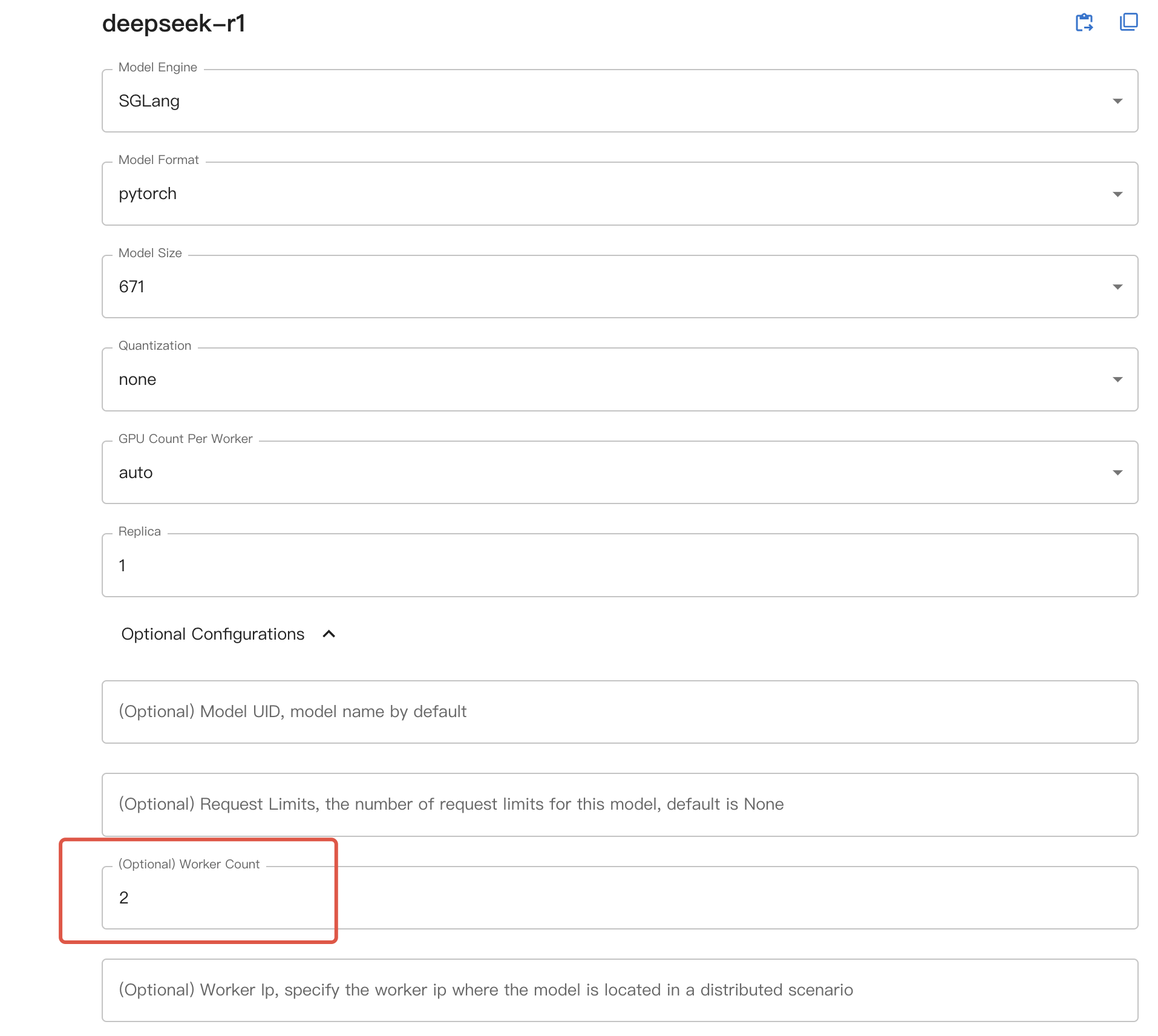
Lors de l’utilisation de l’inférence distribuée, GPU count dans l’interface Web UI ou --n-gpu dans la ligne de commande représente désormais le nombre de GPU par nœud de travail.