Image#
Apprenez à utiliser Xinference pour générer des images.
Introduction#
L’API Images propose deux méthodes pour interagir avec les images :
L’point de terminaison texte-vers-image crée des images à partir de zéro selon le texte.
Le point de terminaison image-à-image vous permet de générer des variantes d’une image donnée.
Point de terminaison API |
Point de terminaison compatible OpenAI |
|---|---|
Text-to-Image API |
/v1/images/generations |
Image-to-image API |
/v1/images/variations |
Liste des modèles supportés#
L’API texte-à-image prend en charge les modèles suivants dans Xinference :
sd-turbo
sdxl-turbo
stable-diffusion-v1.5
stable-diffusion-xl-base-1.0
sd3-medium
sd3.5-medium
sd3.5-large
sd3.5-large-turbo
FLUX.1-schnell
FLUX.1-dev
Kolors
hunyuandit-v1.2
hunyuandit-v1.2-distilled
cogview4
Qwen-Image
Liste des modèles pris en charge
Flux.1-Kontext-dev
Qwen-Image-Edit
Démarrage rapide#
Texte à image#
Vous pouvez essayer d’utiliser l’API Text-to-image via cURL, OpenAI Client ou Xinference.
curl -X 'POST' \
'http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1/images/generations' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "<MODEL_UID>",
"prompt": "an apple",
}'
import openai
client = openai.Client(
api_key="cannot be empty",
base_url="http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
client.images.generate(
model=<MODEL_UID>,
prompt="an apple"
)
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("<MODEL_UID>")
input_text = "an apple"
model.text_to_image(input_text)
{
"created": 1697536913,
"data": [
{
"url": "/home/admin/.xinference/image/605d2f545ac74142b8031455af31ee33.jpg",
"b64_json": null
}
]
}
Génération d’image à partir d’image#
L’API image-à-image simule l’API de création de variantes d’images d’OpenAI <https://platform.openai.com/docs/api-reference/images/createVariation>. Nous pouvons essayer d’utiliser l’API image-à-image via cURL, le client OpenAI ou le client Python de Xinference.
curl -X 'POST' \
'http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1/images/variations' \
-F model=<MODEL_UID> \
-F image=@xxx.jpg \
-F prompt="an apple"
import openai
client = openai.Client(
api_key="cannot be empty",
base_url="http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
client.images.create_variation(
model=<MODEL_UID>,
image=open("image_edit_original.png", "rb"),
prompt="an apple"
)
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("<MODEL_UID>")
input_text = "an apple"
with open("xxx.jpg", "rb") as f:
model.image_to_image(f.read(), input_text)
{
"created": 1697536913,
"data": [
{
"url": "/home/admin/.xinference/image/605d2f545ac74142b8031455af31ee33.jpg",
"b64_json": null
}
]
}
Optimisation mémoire des grands modèles d’images (par exemple SD3-Medium, FLUX.1)#
Note
À partir de la v0.16.1, Xinference active par défaut la quantification pour les grands modèles d’images tels que les séries Flux.1 et SD3.5. Si vous utilisez une version de Xinference plus récente que la v0.16.1, vous n’avez rien à faire pour exécuter ces grands modèles d’images sur une machine avec une petite mémoire GPU.
Les paramètres supplémentaires utiles passés au modèle de chargement incluent :
--cpu_offload True: spécifierTruedéchargera les composants du modèle vers le CPU pendant l’inférence pour économiser de la mémoire, ce qui entraînera une légère augmentation de la latence de l’inférence. Le déchargement du modèle déplace uniquement les composants du modèle vers le GPU lorsqu’ils doivent être exécutés, tout en maintenant le reste des composants sur le CPU.--quantize_text_encoder <text encoder layer>: nous utilisons la bibliothèquebitsandbytespour charger et quantifier le codeur textuel T5-XXL avec une précision de 8 bits. Cela vous permet de continuer à utiliser l’intégralité du codeur textuel avec un impact minime sur les performances.--text_encoder_3 None, pour sd3-medium, supprimer l’encodeur de texte T5-XXL de 4,7 milliards de paramètres, gourmand en mémoire lors de l’inférence, peut réduire considérablement les besoins en mémoire, avec seulement une légère perte de performance.--transformer_nf4 True:utiliser la quantification nf4 pour le transformateur.--quantize: n’affecte que le moteur MLX sur Mac. Flux.1-dev et Flux.1-schnell utilisent le moteur MLX pour les calculs sur Mac, etquantizepeut être utilisé pour quantifier le modèle.
Pour le WebUI, il suffit d’ajouter des paramètres supplémentaires, par exemple, ajouter la clé cpu_offload avec la valeur True pour activer le déchargement CPU.
Les paramètres utilisés par défaut depuis la v0.16.1 sont listés ci-dessous.
Modèle |
quantize_text_encoder |
quantize |
transformer_nf4 |
|---|---|---|---|
FLUX.1-dev |
text_encoder_2 |
True |
False |
FLUX.1-schnell |
text_encoder_2 |
True |
False |
sd3-medium |
text_encoder_3 |
N/A |
False |
sd3.5-medium |
text_encoder_3 |
N/A |
False |
sd3.5-large |
text_encoder_3 |
N/A |
True |
sd3.5-large-turbo |
text_encoder_3 |
N/A |
True |
Qwen-Image |
text_encoder |
N/A |
False |
Qwen-Image-Edit |
text_encoder |
N/A |
False |
Note
Si vous souhaitez désactiver certaines quantifications, il suffit de définir l’option correspondante sur False. Par exemple, pour l’interface Web UI, définissez la clé quantize_text_encoder et la valeur False, ou pour la ligne de commande, spécifiez --quantize_text_encoder False pour désactiver la quantification du text encoder.
Pour CogView4, nous avons constaté que la quantification a un impact important sur le modèle. Par conséquent, lorsque la mémoire vidéo est limitée, nous recommandons d’activer l’option CPU offload dans l’interface Web UI, et de spécifier --cpu_offload True lors du chargement du modèle en ligne de commande.
Format de fichier GGUF#
Le format de fichier GGUF offre une multitude d’options de quantification pour le module transformer. Pour utiliser un fichier GGUF, vous pouvez spécifier l’option supplémentaire gguf_quantization dans l’interface Web, ou --gguf_quantization en ligne de commande, afin d’activer la quantification GGUF pour les modèles pris en charge nativement par Xinference. Voici les modèles pris en charge intégrés.
Modèle |
Prend en charge le format de quantification GGUF |
|
|---|---|---|
FLUX.1-dev |
F16, Q2_K, Q3_K_S, Q4_0, Q4_1, Q4_K_S, Q5_0, Q5_1, Q5_K_S, Q6_K, Q8_0 |
|
FLUX.1-schnell |
F16, Q2_K, Q3_K_S, Q4_0, Q4_1, Q4_K_S, Q5_0, Q5_1, Q5_K_S, Q6_K, Q8_0 |
|
sd3.5-medium |
F16, Q3_K_M, Q3_K_S, Q4_0, Q4_1, Q4_K_M, Q4_K_S, Q5_0, Q5_1, Q5_K_M, Q5_K_S, Q6_K, Q8_0 |
|
sd3.5-large |
F16, Q4_0, Q4_1, Q5_0, Q5_1, Q8_0 |
|
sd3.5-large-turbo |
F16, Q4_0, Q4_1, Q5_0, Q5_1, Q8_0 |
|
Qwen-Image |
F16, Q3_K_M, Q3_K_S, Q4_0, Q4_1, Q4_K_M, Q4_K_S, Q5_0, Q5_1, Q5_K_M, Q5_K_S, Q6_K, Q8_0 |
|
Qwen-Image-Edit |
Q2_K, Q3_K_M, Q3_K_S, Q4_0, Q4_1, Q4_K_M, Q4_K_S, Q5_0, Q5_1, Q5_K_M, Q5_K_S, Q6_K, Q8_0 |
|
Qwen-Image-Edit-2509 |
Q2_K, Q3_K_M, Q3_K_S, Q4_0, Q4_1, Q4_K_M, Q4_K_S, Q5_0, Q5_1, Q5_K_M, Q5_K_S, Q6_K, Q8_0 |
|
Note
Nous recommandons fortement d’activer l’option supplémentaire cpu_offload dans l’interface WebUI en la définissant sur True, ou, pour la ligne de commande, de spécifier --cpu_offload True.
Par exemple :
xinference launch --model-name FLUX.1-dev --model-type image --gguf_quantization Q2_K --cpu_offload True
Avec la quantification Q2_K, vous n’avez besoin que d’environ 5 Go de mémoire vidéo pour exécuter Flux.1-dev.
Pour les modèles qui ne prennent pas en charge la quantification GGUF nativement, ou si vous souhaitez télécharger vous-même un fichier GGUF, vous pouvez spécifier l’option supplémentaire gguf_model_path dans l’interface Web UI ou utiliser la ligne de commande avec --gguf_model_path /path/to/model_quant.gguf.
Lightning LORA prend en charge#
Lightning LORA distille le modèle sous forme de LoRA, réduisant le nombre d’étapes d’inférence tout en maintenant les performances du modèle et en augmentant considérablement la vitesse d’inférence. Les modèles suivants prennent actuellement en charge ce LoRA :
Modèle |
Version Lightning prise en charge |
|
|---|---|---|
Qwen-Image |
4steps-V1.0-bf16, 4steps-V1.0, 8steps-V1.0, 8steps-V1.1-bf16, 8steps-V1.1 |
|
Qwen-Image-Edit |
4steps-V1.0-bf16, 4steps-V1.0, 8steps-V1.0-bf16, 8steps-V1.0 |
|
Qwen-Image-Edit-2509 |
4steps-V1.0-bf16, 4steps-V1.0-fp32, 8steps-V1.0-bf16, 8steps-V1.0-fp32 |
|
4 étapes ou 8 étapes fait référence au nombre d’étapes d’inférence (num_inference_steps). Lorsque lightning_version est spécifié, Xinference définit automatiquement le nombre d’étapes d’inférence.
Lors de l’utilisation, vous pouvez sélectionner la version Lightning dans l’interface ou la spécifier via la ligne de commande.
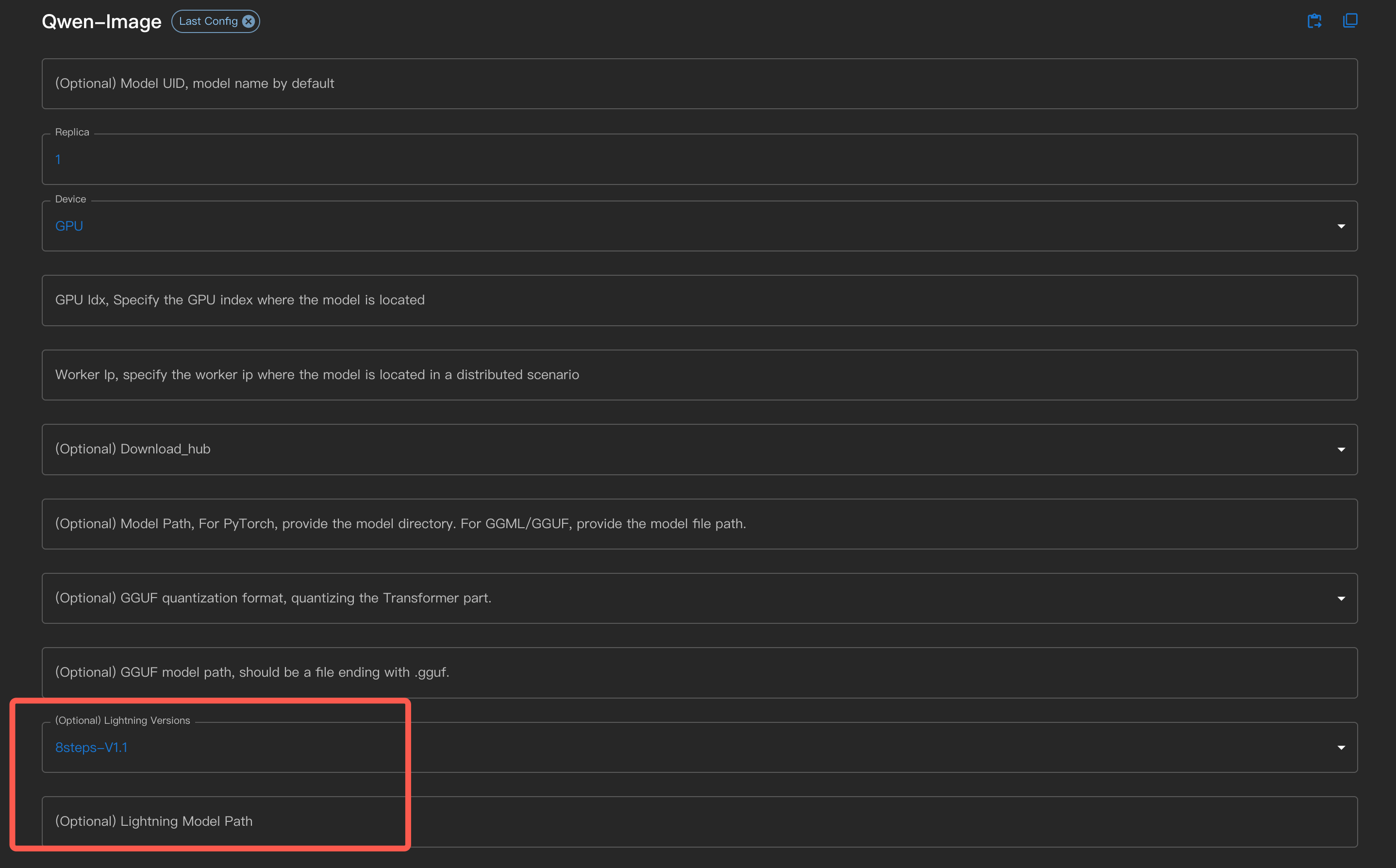
Dans la ligne de commande, utilisez --lightning_version <version>.
Pour les utilisateurs qui ont téléchargé eux-mêmes le fichier LoRA lightning, ils peuvent le spécifier dans l’interface via Lightning Model Path, ou utiliser le paramètre de ligne de commande --lightning_model_path.
Par exemple, en utilisant 4steps-V1.0, le temps d’inférence est passé de 34 secondes à 3 secondes.
OCR#
L’API OCR accepte les octets d’une image et retourne le texte OCR.
Vous pouvez essayer l’API OCR via cURL ou le client Python de Xinference.
curl -X 'POST' \
'http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1/images/ocr' \
-F model=<MODEL_UID> \
-F 'kwargs={"model_size":"large"}' \
-F image=@xxx.jpg
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("<MODEL_UID>", model_size="large")
with open("xxx.jpg", "rb") as f:
model.ocr(f.read())
<OCR result string>