Environnement virtuel du modèle#
Ajouté dans la version v1.5.0.
Contexte#
Certains modèles ne sont plus maintenus après leur publication, et les versions des bibliothèques dont ils dépendent restent obsolètes. Par exemple, le modèle GOT-OCR2 dépend toujours de transformers 4.37.2. Si cette bibliothèque est mise à jour vers une nouvelle version, le modèle ne fonctionnera plus correctement ; tandis que de nombreux nouveaux modèles nécessitent la version la plus récente de transformers. Cette différence de version peut entraîner des conflits de dépendances.
Solution#
Pour résoudre ce problème, nous avons introduit la fonctionnalité d’environnement virtuel de modèle.
Installez les dépendances nécessaires pour cette fonctionnalité à l’aide de la commande suivante.
# all
pip install 'xinference[all]'
# or virtualenv
pip install 'xinference[virtualenv]'
Activez cette fonctionnalité en définissant la variable d’environnement XINFERENCE_ENABLE_VIRTUAL_ENV=1.
Exemple d’utilisation :
# For command line
XINFERENCE_ENABLE_VIRTUAL_ENV=1 xinference-local ...
# For Docker
docker run -e XINFERENCE_ENABLE_VIRTUAL_ENV=1 ...
Avertissement
Cette fonctionnalité nécessite une connexion réseau ou l’utilisation d’un service de miroir PyPI auto-hébergé.
Xinference hérite par défaut de la configuration actuelle de pip.
Note
Attention : lors du démarrage du moteur vLLM/SgLang en environnement virtuel, en cas d’erreur cuDNN, vous pouvez configurer :
export LD_LIBRARY_PATH=$CONDA_PREFIX/lib/python3.12/site-packages/nvidia/cudnn/lib:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=$CONDA_PREFIX/lib/python3.12/site-packages/nvidia/cusparselt/lib:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=$CONDA_PREFIX/lib/python3.12/site-packages/nvidia/nccl/lib:$LD_LIBRARY_PATH
Modifié dans la version v2.0.0: À partir de Xinference v2.0, la fonction d’environnement virtuel de modèle est activée par défaut (c’est-à-dire que la valeur par défaut de XINFERENCE_ENABLE_VIRTUAL_ENV est 1 ).
Pour désactiver globalement cette fonctionnalité, définissez XINFERENCE_ENABLE_VIRTUAL_ENV=0 lors du démarrage de Xinference.
Une fois cette fonction activée, Xinference crée automatiquement un environnement virtuel dédié pour chaque modèle lors de son chargement, et installe les dépendances correspondantes dans cet environnement. Cela permet d’éviter les conflits de dépendances entre les modèles et assure que chaque modèle s’exécute de manière indépendante dans des environnements isolés.
Gestion des environnements virtuels (v2.0)#
Bascule globale#
À partir de la version 2.0, l’environnement virtuel est activé par défaut. Vous pouvez toujours modifier cette option via les paramètres globaux :
# Enable globally (default)
XINFERENCE_ENABLE_VIRTUAL_ENV=1 xinference-local -H 0.0.0.0 -p 9997
# Disable globally
XINFERENCE_ENABLE_VIRTUAL_ENV=0 xinference-local -H 0.0.0.0 -p 9997
Remplacements par modèle au démarrage#
Au démarrage du modèle, vous pouvez remplacer les paramètres globaux :
# Force enable for this model
xinference launch -n qwen2.5-instruct --model-engine transformers --enable-virtual-env
# Force disable for this model
xinference launch -n qwen2.5-instruct --model-engine transformers --disable-virtual-env
Ajouter ou remplacer un paquet au démarrage#
Dans la ligne de commande, utilisez --virtual-env-package ou -vp pour spécifier une version de paquet unique.
xinference launch -n qwen2.5-instruct --model-engine transformers \
--virtual-env-package transformers==4.46.3 \
--virtual-env-package accelerate==0.33.0
Si le paquet spécifié existe déjà dans la liste des paquets de l’environnement virtuel par défaut du modèle, la version que vous spécifiez remplacera la version par défaut, au lieu de s’ajouter à la liste.
Emplacement de stockage#
Par défaut, l’environnement virtuel du modèle est stocké dans le chemin suivant :
Avant v1.6.0 : XINFERENCE_HOME / virtualenv / {model_name}
De la v1.6.0 à la v1.13.0 : XINFERENCE_HOME / virtualenv / v2 / {model_name}
À partir de la version 1.14.0 : XINFERENCE_HOME / virtualenv / v3 / {model_name} / {python_version}
Depuis v2.0 : XINFERENCE_HOME / virtualenv / v4 / {model_name} / {model_engine} / {python_version}
Ignorer les bibliothèques déjà installées#
Ajouté dans la version v1.8.1: Cette fonctionnalité nécessite xoscar >= 0.7.12, qui est la version minimale de Xoscar requise par Xinference v1.8.1.
xinference utilise l’outil uv pour créer un environnement virtuel et définit les system site-packages Python actuels comme environnement de base. Par défaut, uv ne vérifie pas si des paquets existent déjà dans l’environnement système, mais réinstalle toutes les dépendances dans l’environnement virtuel. Cette approche permet une meilleure isolation par rapport aux paquets système, mais peut entraîner des installations redondantes, un temps d’initialisation plus long et une augmentation de l’occupation disque.
À partir de v1.8.1, une fonctionnalité expérimentale est fournie : en définissant la variable d’environnement XINFERENCE_VIRTUAL_ENV_SKIP_INSTALLED=1, uv ignorera les paquets déjà existants dans les site-packages système.
Modifié dans la version v2.0: Cette fonctionnalité est activée par défaut dans la version v2.0. Pour la désactiver, veuillez définir XINFERENCE_VIRTUAL_ENV_SKIP_INSTALLED=0.
Avantage#
Évitez de réinstaller de grandes dépendances (par exemple
torch+CUDA).Accélérer la création d’environnements virtuels.
Réduire l’occupation de l’espace disque.
Utiliser#
# Enable experimental feature
# For command line
XINFERENCE_ENABLE_VIRTUAL_ENV=1 XINFERENCE_VIRTUAL_ENV_SKIP_INSTALLED=1 xinference-local ...
# For docker
docker run -e XINFERENCE_ENABLE_VIRTUAL_ENV=1 -e XINFERENCE_VIRTUAL_ENV_SKIP_INSTALLED=1 ...
Comparaison des performances#
Avec le modèle CosyVoice 0.5B comme exemple :
Lorsque cette fonction n’est pas activée
Installed 98 packages in 187ms
+ aiohappyeyeballs==2.6.1
+ aiohttp==3.12.13
...
+ torch==2.7.1
...
+ yarl==1.20.1
+ zipp==3.23.0
Après avoir activé cette fonction
Installed 7 packages in 12ms
+ diffusers==0.29.0
+ hf-xet==1.1.5
+ huggingface-hub==0.33.2
+ importlib-metadata==8.7.0
+ pillow==11.3.0
+ typing-extensions==4.14.0
+ urllib3==2.5.0
Chargement du modèle : activer l’environnement virtuel et personnaliser les dépendances#
Ajouté dans la version v1.8.1.
À partir de la v1.8.1, nous prenons en charge le chargement d’un environnement virtuel de commutation pour un modèle unique et la possibilité de remplacer les paramètres par défaut du modèle par des dépendances de paquets personnalisées.
Espace virtuel du modèle de commutation#
Lors du chargement d’un modèle, vous pouvez spécifier si l’environnement virtuel du modèle doit être activé. Si cela n’est pas précisé, la configuration des variables d’environnement est suivie par défaut.
Dans l’interface Web, cette fonction peut être activée ou désactivée via un interrupteur de paramétrage facultatif.
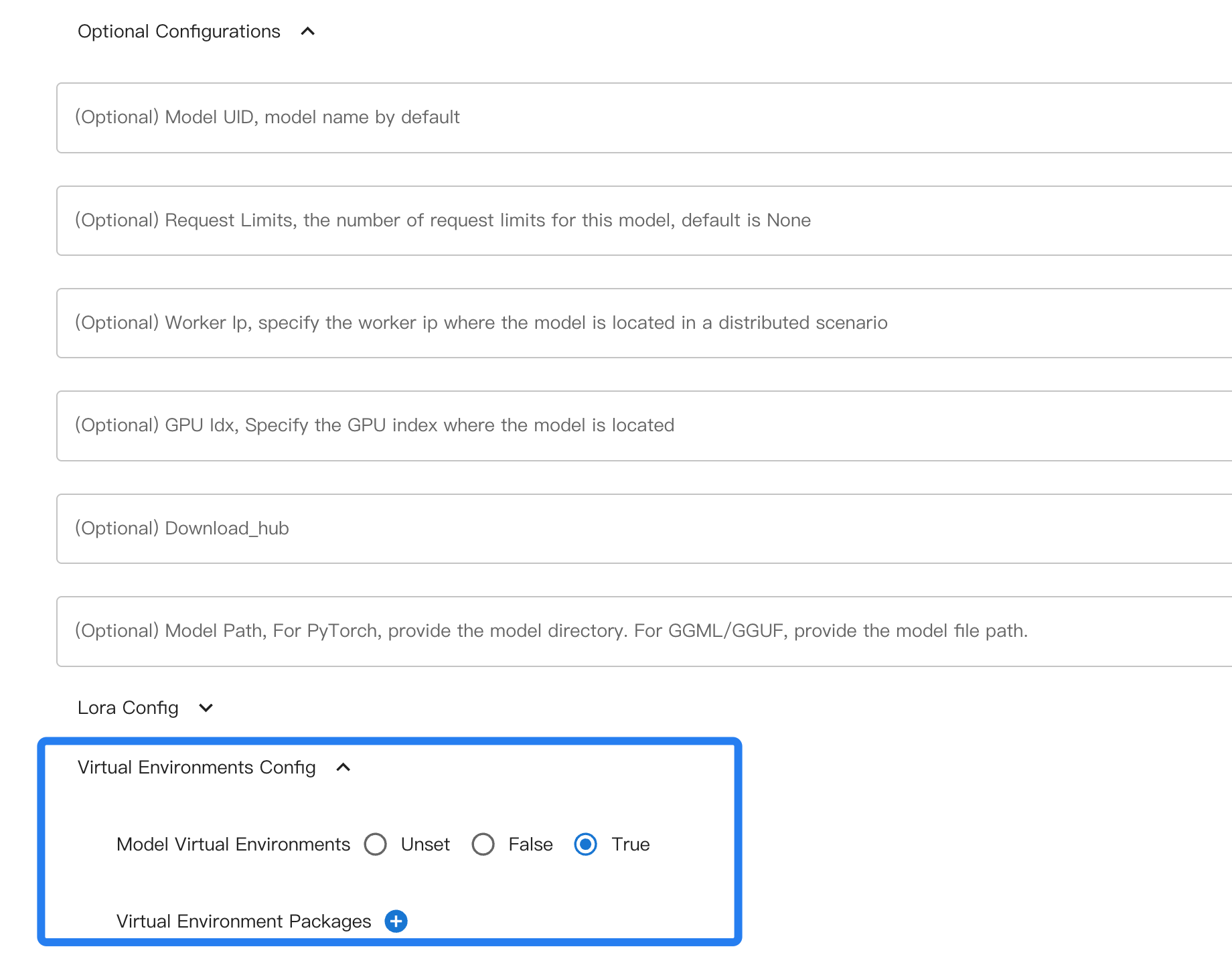
Lors du chargement en ligne de commande, utilisez l’option --enable-virtual-env pour activer l’environnement virtuel, et l’option --disable-virtual-env pour le désactiver.
Exemple d’utilisation :
xinference launch xxx --enable-virtual-env
Définir les dépendances des paquets de l’environnement virtuel#
Pour les modèles pris en charge, Xinference a déjà défini les dépendances de paquets et les exigences de version dans l’environnement virtuel. Cependant, si vous devez spécifier une version particulière ou installer des dépendances supplémentaires, vous pouvez les fournir manuellement lors du chargement du modèle.
Dans l’interface utilisateur Web, vous pouvez cliquer sur l’icône plus (+) au même emplacement que l’interrupteur de l’environnement virtuel pour ajouter des dépendances personnalisées.
En ligne de commande, utilisez --virtual-env-package ou -vp pour spécifier une version de paquet unique.
Exemple d’utilisation :
xinference launch xxx --virtual-env-package transformers==4.54.0
En plus de la méthode standard de spécification des dépendances de paquets (comme transformers==xxx), Xinference prend également en charge certaines syntaxes étendues.
#system_xxx#: Utilisez la même version que les site packages système, par exemple#system_numpy#, pour garantir que la version du paquet installé correspond à celle de numpy dans les site packages système, évitant ainsi les conflits de dépendances.
Gestion des environnements virtuels#
Ajouté dans la version v1.14.0.
Xinference offre des fonctionnalités complètes de gestion d’environnements virtuels, vous permettant de créer un environnement Python indépendant pour chaque modèle afin de répondre à des besoins spécifiques en matière de dépendances de paquets.
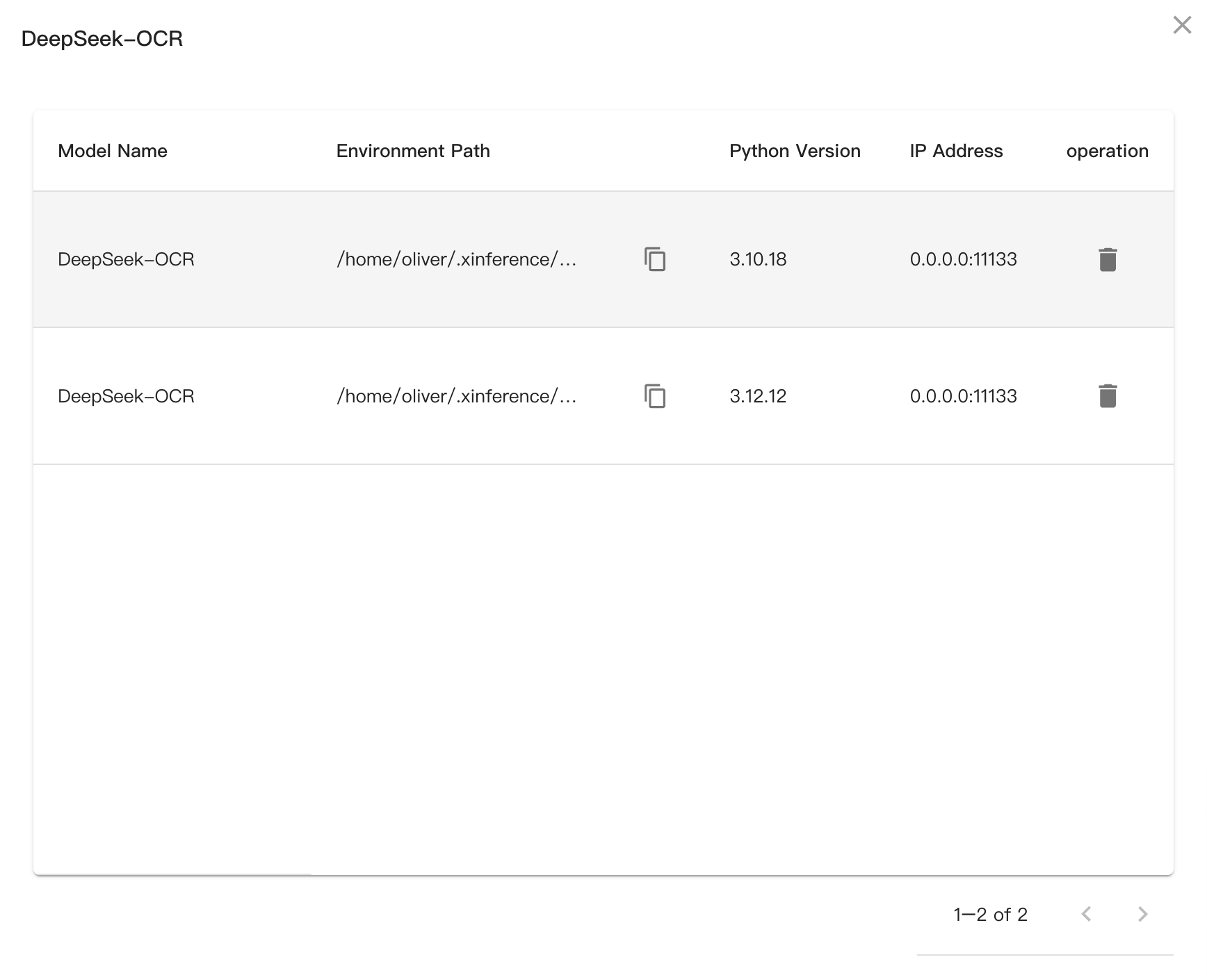
Fonctionnalités principales#
Prise en charge de plusieurs versions de Python : Chaque modèle peut disposer d’un environnement virtuel avec une version de Python différente (par exemple Python 3.10.18, 3.11.5), assurant la compatibilité avec les exigences de divers modèles.
Isolement des dépendances : chaque environnement virtuel contient son propre ensemble de paquets indépendant, empêchant les conflits de dépendances entre différents modèles.
Opérations de gestion#
Lister les environnements virtuels : Afficher tous les environnements virtuels du cluster, avec la possibilité de filtrer par nom de modèle ou adresse IP du nœud de travail.
Création de l’environnement : Créée automatiquement lors du démarrage du modèle avec enable_virtual_env=true. Le système détecte la version actuelle de Python et crée un environnement indépendant contenant les paquets requis.
Supprimer un environnement : Vous pouvez supprimer un environnement virtuel spécifique par nom de modèle et version Python optionnelle, ou supprimer tous les environnements d’un modèle.
Format JSON de ModelHub (applicable aux modèles Xinference)#
Si vous prévoyez d’ajouter un modèle au Model Hub de Xinference, veuillez définir un bloc virtualenv dans le JSON du modèle. Depuis la version v2.0 (flux v4), il est recommandé d’utiliser des marqueurs sensibles au moteur, afin qu’un seul fichier JSON puisse couvrir plusieurs moteurs.
Règle importante : si le nouveau modèle prend en charge un moteur spécifique, il doit inclure au moins une entrée de package de ce moteur dans virtualenv.packages, avec un marqueur ajouté (par exemple #engine# == "vllm"). Lorsque l’environnement virtuel est activé, la vérification de disponibilité du moteur repose sur ces marqueurs pour validation.
{
"virtualenv": {
"packages": [
"#transformers_dependencies# ; #engine# == \"transformers\"",
"#vllm_dependencies# ; #engine# == \"vllm\"",
"#sglang_dependencies# ; #engine# == \"sglang\"",
"#llama_cpp_dependencies# ; #engine# == \"llama.cpp\"",
"#mlx_dependencies# ; #engine# == \"mlx\"",
"#system_numpy# ; #engine# == \"vllm\""
]
}
}
packages(obligatoire) : liste de chaînes ou de marqueurs d’exigence pip.inherit_pip_config(par défauttrue) : si un fichier de configuration pip système existe, en hérite les paramètres.index_url/extra_index_url/find_links/trusted_host: Contrôle des index et miroirs pip.index_strategy: transmis à l’installateur de l’environnement virtuel (utilisé par certains moteurs).no_build_isolation: commutateur d’isolation de construction pip pour les constructions complexes.
Utilisation des valeurs par défaut du moteur d’injection de placeholders enveloppés :
#vllm_dependencies##sglang_dependencies##mlx_dependencies##transformers_dependencies##llama_cpp_dependencies##diffusers_dependencies##sentence_transformers_dependencies#
Utilisez #engine# ou #model_engine# pour la comparaison (sensible à la casse). Les valeurs du moteur sont transmises en minuscules en interne, il est donc recommandé d’utiliser des valeurs en minuscules, par exemple #engine# == "vllm" ou #engine# == "transformers".