multimodal#
Apprenez à utiliser LLM pour traiter des images et de l’audio.
vue#
Avec la capacité vision, vous pouvez permettre au modèle de recevoir des images et de répondre à des questions les concernant. Dans Xinference, cela signifie que certains modèles peuvent traiter des entrées d’images lors des dialogues via l’API Chat.
Liste des modèles pris en charge#
Voici les modèles prenant en charge la fonctionnalité vision dans Xinference :
qwen-vl-chat
deepseek-vl-chat
omnilmm
cogvlm2
MiniCPM-Llama3-V 2.5
glm-edge-v
Démarrage rapide#
Le modèle peut obtenir une image de deux manières principales : en transmettant un lien vers l’image ou en passant directement une image encodée en base64 dans la requête.
Exemple d’utilisation du client OpenAI#
import openai
client = openai.Client(
api_key="cannot be empty",
base_url=f"http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
response = client.chat.completions.create(
model="<MODEL_UID>",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": "http://i.epochtimes.com/assets/uploads/2020/07/shutterstock_675595789-600x400.jpg",
},
},
],
}
],
)
print(response.choices[0])
Télécharger une image encodée en Base64#
import openai
import base64
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Path to your image
image_path = "path_to_your_image.jpg"
# Getting the base64 string
b64_img = encode_image(image_path)
client = openai.Client(
api_key="cannot be empty",
base_url=f"http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
response = client.chat.completions.create(
model="<MODEL_UID>",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{b64_img}",
},
},
],
}
],
)
print(response.choices[0])
Limiter le nombre d’images par tour de conversation#
Pour les modèles visuels utilisant le backend VLLM, vous pouvez limiter le nombre d’images pouvant être traitées par tour de dialogue via le paramètre limit_mm_per_prompt. Cela permet de contrôler l’utilisation de la mémoire et d’améliorer les performances.
# Launch model with image count limitation using Python client
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
# Launch model and set maximum 4 images per conversation turn
model_uid = client.launch_model(
model_name="qwen2.5-vl-instruct",
model_engine="vLLM",
model_format="pytorch",
quantization="none",
model_size_in_billions=3,
limit_mm_per_prompt="{\"image\": 4}"
)
Ou, vous pouvez lancer le modèle en ligne de commande :
# Launch model with image count limitation using CLI
xinference launch \
--model-engine vLLM \
--model-name qwen2.5-vl-instruct \
--size-in-billions 3 \
--model-format pytorch \
--quantization none \
--limit_mm_per_prompt "{\"image\":4}"
Pour l’interface Web, vous pouvez définir le paramètre limit_mm_per_prompt dans le formulaire du moteur vLLM :
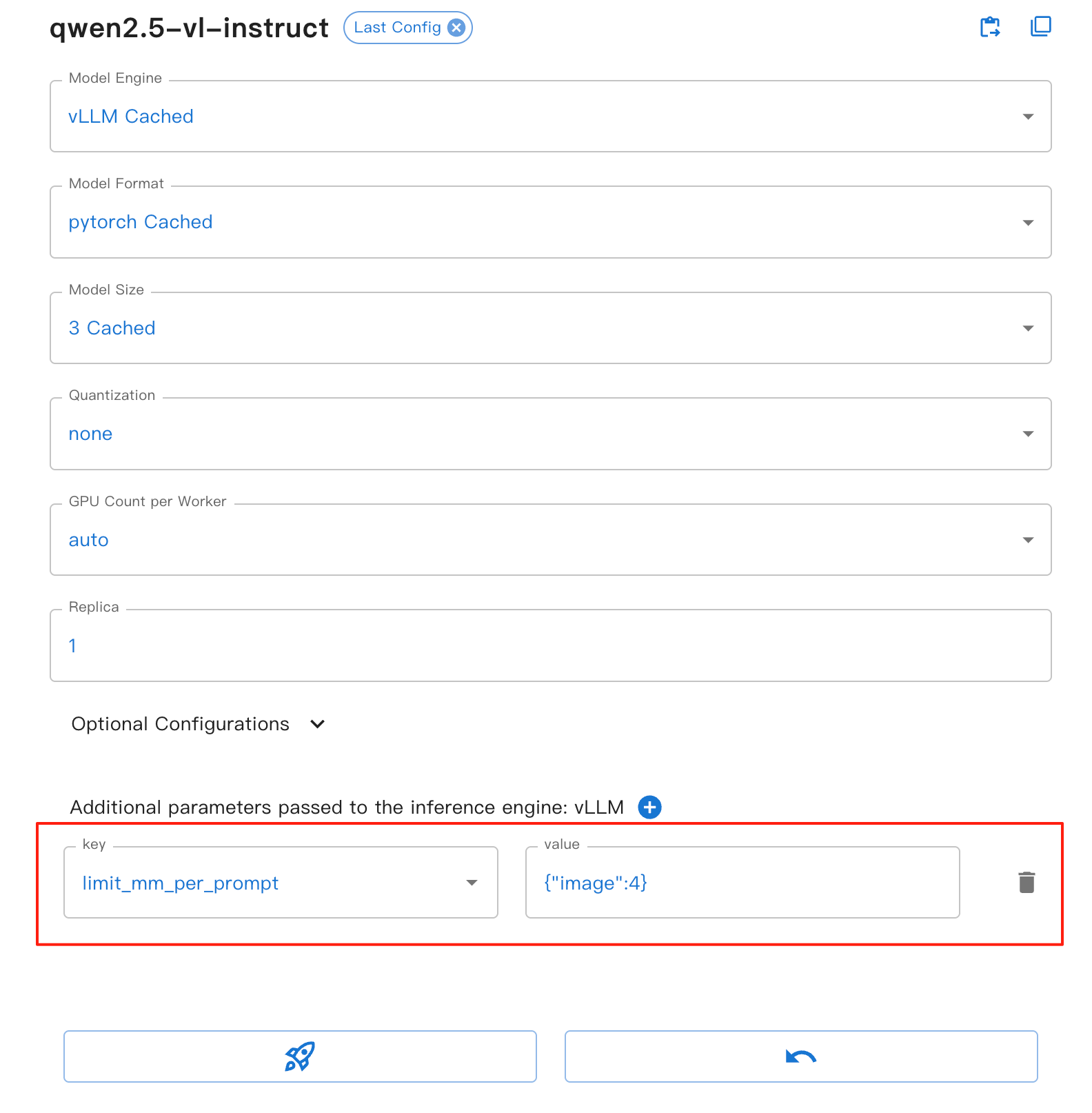
Ce paramètre offre les avantages suivants :
image : Définir le nombre maximal d’images autorisées par tour de dialogue
Aide à prévenir les débordements de mémoire, en particulier lors du traitement de plusieurs images.
Améliorer la stabilité et les performances de l’inférence du modèle.
Applicable à tous les modèles visuels basés sur VLLM
Note
Le paramètre limit_mm_per_prompt est uniquement effectif lors de l’utilisation du backend VLLM. Si votre modèle utilise un autre backend, ce paramètre sera ignoré.
Vous pouvez trouver plus d’exemples des capacités de vision dans le notebook du tutoriel.
Voici un exemple d’utilisation de qwen-vl-chat pour apprendre à exploiter les capacités visuelles des LLM.
Audio#
Grâce à la fonctionnalité « audio », votre modèle peut recevoir de l’audio et effectuer une analyse audio ou générer directement des réponses textuelles basées sur des instructions vocales. Dans Xinference, cela signifie que certains modèles peuvent traiter des entrées audio lors des conversations via l’API de chat.
Liste des modèles pris en charge#
La fonctionnalité « Audio » dans Xinference prend en charge les modèles suivants :
Démarrage rapide#
L’audio peut être fourni au modèle de deux manières principales : en passant un lien image ou en transmettant directement une URL audio dans la requête.
Chat avec audio#
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model(<MODEL_UID>)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
{
"type": "audio",
"audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/glass-breaking-151256.mp3",
},
{"type": "text", "text": "What's that sound?"},
],
},
{"role": "assistant", "content": "It is the sound of glass shattering."},
{
"role": "user",
"content": [
{"type": "text", "text": "What can you do when you hear that?"},
],
},
{
"role": "assistant",
"content": "Stay alert and cautious, and check if anyone is hurt or if there is any damage to property.",
},
{
"role": "user",
"content": [
{
"type": "audio",
"audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/1272-128104-0000.flac",
},
{"type": "text", "text": "What does the person say?"},
],
},
]
print(model.chat(messages))